May 28, 2020
A Look at Scales of Measurement
—A closer look at scales of measurement.
In Data Measurement and Analysis for Software Engineers, I discuss the first of four webinars on measurment by Dennis J. Frailey. A key point in the first webinar is the importance of understanding the scales used for measurement and the statistical techniques usable on those scales.
Here, I take a look at scales of measurement and Stanley S. Stevens’ article On the Theory of Scales of Measurement. Stevens was interested in measuring auditory sensation. I’m interested in defect severity. Both measures have some surprising commonality.
Stevens defines measurement as
the assignment of numerals to objects or events according to rules.
Stevens wanted to measure the subjective magnititude of auditory sensation against a scale with the formal properties of other basic scales. Basic scales include those used to measure weight and length.
The rationale for Stevens’ focus on scales of measurement was the recognition that
- rules can be used to assign numerals to attributes of an object.
- different rules create different kinds of scales for these attributes.
- different scales create different kinds of measurement on these attributes.
These differences require definition of
- the rules for assigning measurement,
- the mathematical properties (or group structure) of the scales and
- the statistcal operations applicable to each scale.
Rules for Specifying Severity
Defect severity is an example of an ordinal scale. An ordinal scale includes:
- rules for specifying severity.
- the properties of a nominal scale for severity, that permit
- contigency correlation for severity and
- hypothesis testing of defect severity. This scale has properties that permit the determination of equality.
- the properties of an ordinal scale for severity. These properties permit the determination of greater or less than.
An example where rules are needed is the determination of the severity of a defect. Without rules, severity level reflects the reporter’s intuitive notion of severity. This notion is likely to differ by reporter and possibly by the same reporter over time.
Rules ensure that different reporters consistently apply severity level to defects. Consistently applying severity level ensures that all defects have the same scale of severity. Using the same scale means the mathematical properties of that scale are known. This permits determination of the applicable statistical operations for severity.
The focus on rules is a response to the subjective nature of the measurement. Defect severity is a subjective measure, as shown by the definition of severity (see IEEE Standard Classification for Software Anomalies):
The highest failure impact that the defect could (or did) cause, as determined by (from the perspective of) the organization responsible for software engineering.
This standard defines the following severity levels.

Importantly, this definition seeks a scale of measure that reflects a common prespective of severity.
This common perspective is created using severity level and shared notions of essential operation and of significant impact.
The Properties of a Nominal Scale for Severity
Severity has the properties of a nominal scale. A nominal scale uses numerals (or labels) to create different classes. Stevens’ calls this a nominal scale of Type B. A Type B nominal scale supports the mode (frequency) and hypothesis testing regarding the distribution of cases amongst different classes and contengency correlation.
A hypothesis test might use severity from all releases to determine if overall quality has improved. To be meaningful, this test would require the same rules for assigning severity applied to each release included in the test.
Contigency Correlation for Severity
An example of contengency correlation for defects by release uses two categorical variables: Release and Severity. Release has 2 cases (i.e., R1 and R2); Severity has 5 cases (i.e., Blocking through Inconsequential).
Releases R1 and R2 (the most recent release) have these observed defect counts by severity:1
| Release | Blocking | Critical | Major | Minor | Inconsequential | Total |
|---|---|---|---|---|---|---|
| R1 | 23 (14.4%) | 27 (16.9%) | 41 (25.6%) | 25 (15.6%) | 44 (27.5%) | 160 (52.1%) |
| R2 | 44 (29.9%) | 49 (33.3%) | 7 (4.8%) | 28 (19.0%) | 19 (12.9%) | 147 (47.9%) |
| Total | 67 (21.8%) | 76 (24.8%) | 48 (15.6%) | 53 (17.3%) | 63 (20.5%) | 307 (100.0%) |
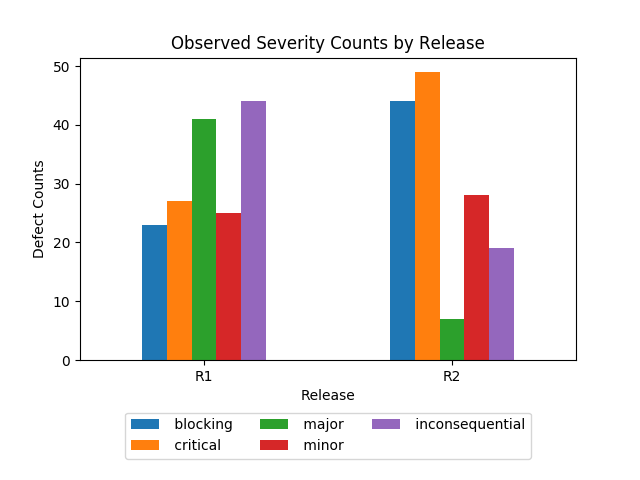
Observed characteristics:
- The totals provide the observed frequency of each severity level using the last two releases. That is, the frequency of Blocking severities is \(67\) out of \(307\) observations.
- The mode severity is Inconsequential, Blocking and Critical for R1, R2 and R1 and R2, respectively.
Releases R1 and R2 have the following expected defect counts by severity:2
| Release | Blocking | Critical | Major | Minor | Inconsequential | Total |
|---|---|---|---|---|---|---|
| R1 | 34.9 (21.8%) | 39.6 (24.8%) | 25.0 (15.6%) | 27.6 (17.3%) | 32.8 (20.5%) | 160 (100.0%) |
| R2 | 32.1 (21.8%) | 36.4 (24.8%) | 23.0 (15.6%) | 25.4 (17.3%) | 30.2 (20.5%) | 147 (100.0%) |
| Total | 67.0 (21.8%) | 76.0 (24.8%) | 48.0 (15.6%) | 53.0 (17.3%) | 63.0 (20.5%) | 307 (100.0%) |
Expected characteristics:
- All expected values are normalized using the frequencies in the total row of the observed table.
- The severity frequency is Critical for R1, R2 and R1 and R2, respectively.
- R1 has lower than expected Blocking, Critical and Minor severity counts than what is observed. Higher than expected in Major and Inconsequential than what is observed.
- R2 has lower than expected Major and Inconsequential severity counts than what is observed.
Graphically, these look like:
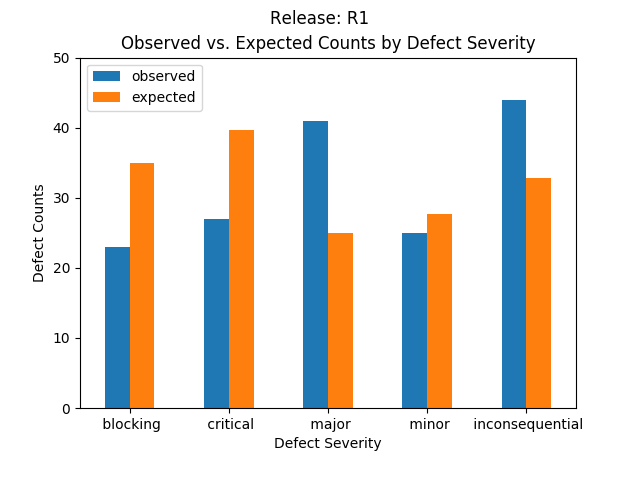
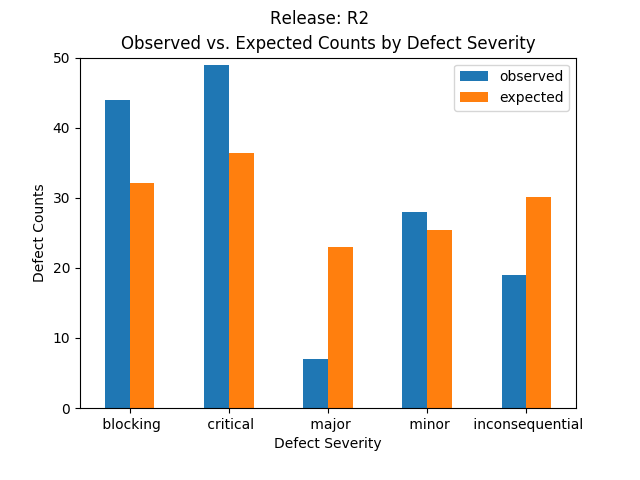
The expected values reflect a proportionality dictated by the frequency of the observations. The next section investigates whether this proportionality has any bearing on the observations.
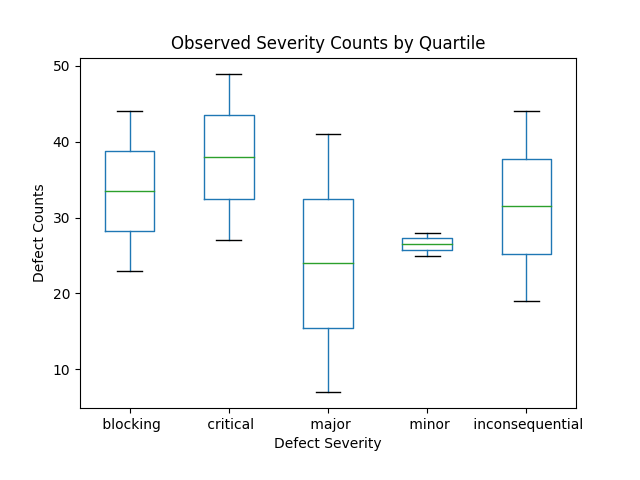
This figure depicts the same observations for R1 and R2 using a box plot.
A box plot shows the maximum and minimum values (the top and bottom crosses), along with the median value (middle of the box). The box top and bottom for the top and bottom 25 pecentiles of the data.
This box plot tells a story of very high Blocking and Critical defects in both releases. It conceals information on the individual releases, for example, has R2 improved?
To understand if R2 is better than R1 the following graphs are helpful.
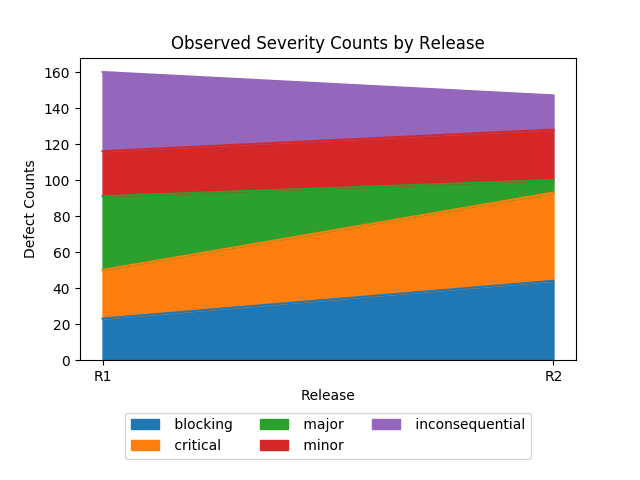
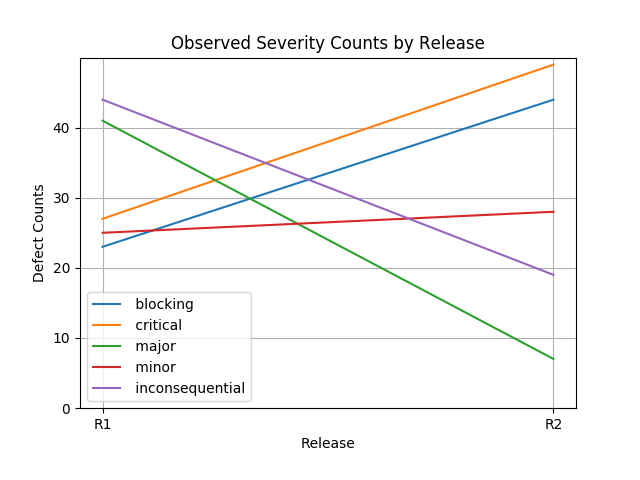
Clearly, R2 is worse than R1 in terms of the introduction of higher severity defects, despite the fact that the defect counts are smaller. (An area plot seems more informative than a stacked bar plot, but both provide the same information.)
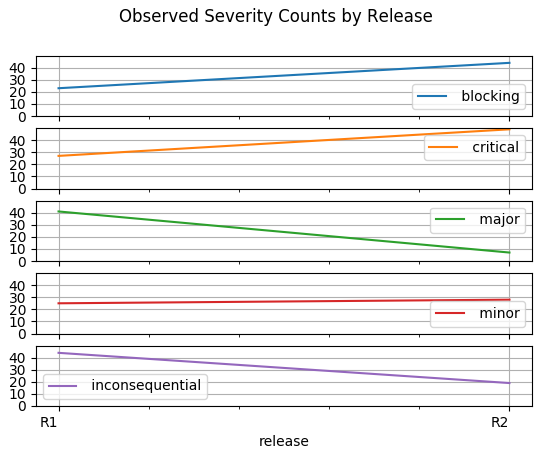
For more emphasis on individual severity counts. (These plots focus on individual severity counts and are less busy than the preceeding line chart.)
Hypothesis Testing on Severity Distributions
A nominal scale permits hypothesis testing of the distribution of the data. Severity is a form of categorical data. Categorical data is divided into groups (e.g., Blocking and Inconsequential).
There are several tests for the analysis of categorical data. The most appropriate one in this case, is the Categorical Distribution. A Categorical Distribution is a generalization of the binomial distribution, called a multinomial distribution.
A binomial distribution is a distribution where a random variable can take on only one of two values (i.e., \(0\) or \(1\)). The number of trials in a binomial is \(n = 1\). A Multinomial distribution where each trial can have an outcome in any one of several categories.
A Categorical Distribution is a vector of length \(k > 0\), where \(k\) is the number of elements in a vector were only one element has the value \(1\). The others have a value of \(0\). The number of trials in a Categorical Distribution is \(n = 1\).
Since a defect can have only one severity level, severity can be viewed as a vector with \(k = 5\) with only one vector element equal to \(1\). (I assume determining severity is a statistically independent event.4)
Statistically, we can use the expected severity to determine the probability for a distribution of severity counts. In the table above, the expected severity is a multinomial distribution.
The probability that these severity counts are \((67, 76, 48, 53, 63)\) is
\[\begin{align} \begin{array}{ccl} Pr(67, 76, 48, 53, 63) & = & \frac{307!}{67! \times 76! \times 48! \times 53! \times 63!}(0.218^{67} \times 0.248^{76} \times 0.156^{48} \times 0.173^{53} \times 0.205^{63}) \\ & = & 1.5432158498238714 \times 10^{-05} \\ \end{array} \end{align}\]The probability of this severity count distribution is \(0.000015,\) or \(3\) in \(200000.\)
There are \(382,313,855\) discrete combinations of severity that sum to \(307.\) (The sum is a constraint placed upon the multinomial distribution, otherwise the probabilities fail to sum to \(1\).) Some statistics on this probability distribution, including counts by severity:
We want to test the null hypothesis \(H_{0}\) is the null hypothesis of homogenity. Homogenity implies that all probabilities for a given category are the same. If the null hypothesis fails, then at least two of the probabilities differ.
For this data set, the \(\chi^{2}\) parameters are as follows.
\[\begin{align} \begin{array}{lcr} \chi^{2} & = & 46.65746412772634 \\ \mbox{p-value} & = & 1.797131557103987e-09 \\ \mbox{Degrees of Freedom} & = & 4 \\ \end{array} \end{align}\]The null hypoyhesis is rejected whenever \(\chi^{2} \ge \chi^{2}_{\alpha, t - 1}\). Clearly, the p-value, an indicator of the likelihood the results support the null hypothesis, is false. Two or more probabilities differ.
The 95% confidence intervals with \(\alpha = 0.05\) and \(Z_{1 - \alpha /2} = 1.96\) are computed: \[ p_{j} \pm Z_{1 - \alpha /2} \times \sqrt{\frac{p_{j} \times (1 - p_{j})}{n}}, \forall \, j, 0 \le j \le n. \]
The confidence intervals for each category are:3
\[\begin{align} \begin{array}{ccc} Blocking & = & 0.218 +/- 0.046 \\ Critical & = & 0.248 +/- 0.048 \\ Major & = & 0.156 +/- 0.041 \\ Minor & = & 0.173 +/- 0.042 \\ Inconsequential & = & 0.205 +/- 0.045 \\ \end{array} \end{align}\]These values provide a confidence interval for each binomial in the multinomial distribution. They are derived using the “Normal Approximation Method” of the Binomial Confidence Interval.
Severity as an Ordinal Scale
Severity is referred to as an ordinal scale. Although it has nominal scale properties, it supports the properties of an ordinal scale. In effect the operations permitted on a scale are cumulatitve–any analysis supported by a nominal scale can be conducted on an ordinal scale.
This cumulative effect of scales is one of two major contributions made by this paper. The other being the definition of measurment itself. Isn’t that cool?
An ordinal scale permits determination of greater or less than–a Blocking defect is more severe than a Critical one. This is why we can say that R2 is worse than R1, despite the reduction in reported defects. There are more Blocking and Critical defects in R2 and these, because of the properties of an ordinal scale, are more severe than the others.
I don’t compute the median of severity in these releases because the distance between ordinals is unclear. Better to stick with frequency as it’s unambiguous.
References
The code used to generate the graphs: GitHub.
Footnotes
1. Severity counts randomly generated courtesy of RANDOM.ORG. R1 and R2 were generated by requesting 5 numbers in the range of 1 through 100, inclusive. ↩
2. Each entry is calculated using the formula \(\frac{\mbox{row total} \times \mbox{column total}}{\mbox{table total}}\). ↩
3. To make statistically valid conclusions a population of 301 is requred for a confidence interval of 1 and confidence level of 99%. This implies that this table is saying something significant regarding the observed severity in both release R1 and R2. ↩
4. Is a defect severity a statistically independent event? It is because the severity of one defect does not influence the severity of any other defect. By contrast, defects are not independent events. For example, a defect in requirements that remains undetected until implementation will generate a collection of related defects. Is the severity of those related defects the same as the one identified in requirements or different? ↩
