A collegue recently provided me a link to Agile Release Trains (ARTs). It’s not an entirely new concept to me, but one that I’ve never had the opportunity to put into practice. ARTs are part of SAFe.
I view the release train model as separating scope from timeline–the idea that if your scope misses the nth train it can go into the nth+1 train. It’s a simple idea with possibly profound implications. SAFe uses ARTs as a key delivery vechicle. SAFe is much, much broader in scope.
To properly understand SAFe, take a look at the SAFe Principles.
A claim in Agile Release Trains is that ARTs are cross-functional. ARTs have all the capabilities—software, hardware, firmware—needed to define, implement, test, deploy, release, and where applicable, operate solutions.
ARTs operate on a set of common principles.
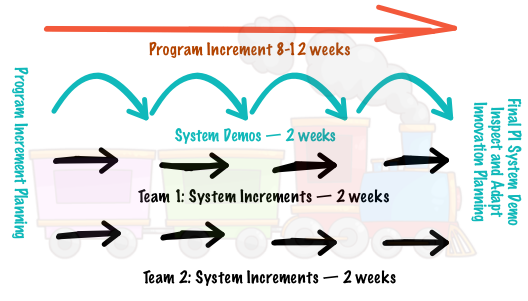
- A fixed schedule as determined by the program increment cadence. All agile teams use the same cadence. A program increment has a fixed length typically 8-12 weeks in duration.
- A system demo of each system increment every 2 weeks. A final system demo occurs at the end of each program increment. That demo includes the inspect and adapt activity.
- Has a known velocity for the program increment.
- Rely upon agile teams.
- Rely upon dedicated people who support the ART, regardless of their functional reporting structure.
- Rely upon face-to-face program increment planning.
- Provide a buffer for innovation and planning including dedicated time for
- program increment planning,
- innovation,
- continuing education and
- infrastructure work.
- Rely upon develop on cadance and release on demand, where demand is driven by a customer. ARTs apply cadence and synchronization to address the variability of Research and Development. Releasing is typically decoupled from the development cadence.
These principles interplay like this.
ARTs have some parallels with Scrum. Indeed, teams involved in ARTs may use Scrum.
The question is can ARTs be accomplished without SAFe? The short answer is they cannot.
The starting point for that question is Essential SAFe. You cannot separate ARTs from SAFe because ARTs are part of the key ingredients of SAFe. Those ingredients are:
- Lean–Agile Principles
- Real Agile Teams and Trains
- Cadence and Synchronization
- Program Increment Planning
- DevOps and Releasability
- System Demo
- Inspect and Adapt
- Architectural Runway
- Innovation and Planning Iteration
- Lean–Agile Leadership
If you want to use ARTs without SAFe you are really interested in a method like Scrum, Extreme Programming, or Kanban. The rationale for using ARTs is that they scale. And that’s the whole point fo SAFe: developing enterprise-scale solutions. The methods listed are focus on individual teams.
